Рис. 2.2. Строение экрана
Прежде чем приступать к изучению ассемблера, нужно усвоить несколько новых терминов, чтобы понимать, о чем вообще идет речь. Эту главу можно считать введением в совершенно новый для вас язык программирования (если же вы знакомы хотя бы с азами ассемблера, то можете лишь бегло пролистать эту и следующую главы, ибо они предназначены, в первую очередь, для новичков, делающих первые шаги в изучении машинного языка).
Нетрудно догадаться, что микропроцессор, будучи куском железа, пусть даже довольно интеллектуального, но все же железа, не способен понимать слова человеческого языка, а тем более - складывать отдельные слова в осмысленные фразы. Как и всякая порядочная электронная машина, он может воспринимать только электрические заряды. Но в отличие от пылесоса микропроцессор принимает заряды одновременно с восьми контактов (строго говоря, микропроцессор обрабатывает гораздо больше сигналов, но сейчас нас интересуют только восемь из них) и в зависимости от поступившего сигнала выполняет то или иное действие.
У каждого из этих восьми контактов может быть лишь два состояния - есть заряд или нет заряда. Поэтому его наличие можно представить как 1, а отсутствие - как 0. Последовательности из единиц и нулей дают числа в двоичном представлении, но их несложно перевести в привычный десятичный формат. Напомним, как это делается на примере числа 00111100. Самый младший разряд (то есть, крайнюю правую цифру) умножаем на 1, второй разряд - на 2, третий - на 4, следующий - на 8 и так далее. Иными словами, значение каждого разряда умножается на 2 в степени n, где n - номер разряда, который может изменяться от 0 до 7 (то есть, говоря научно, 2 - это основание системы счисления). Если вам не очень понятно такое определение, воспользуйтесь простой формулой для перевода нашего двоичного числа в десятичное:
00111100=0ґ128+0ґ64+1ґ32+1ґ16+1ґ8+1ґ4+0ґ2+0ґ1=60Точно так же можно перевести в десятичное и любое другое число, представленное в двоичном формате. Попутно напомним, что разряды двоичных чисел в информатике принято называть битами, а последовательности из 8 битов составляют байты.
Теперь вы вправе спросить, а что же будет, если микропроцессору дать такую команду? В ответ мы напишем похожую строку на хорошо известном вам Бейсике:
LET A=A+1то есть содержимое переменной A увеличивается на единицу. И если последнюю запись понять не так уж трудно, то на свете найдется не так уж много людей, способных не только воспринимать, но и писать достаточно сложные программы, оперируя голыми числами, да еще двоичными. Простой и логичный выход из создавшегося затруднения - заменить все коды машинного языка человеческими словами или, хотя бы сокращениями, поставив каждой команде микропроцессора в соответствие единственное обозначение. Именно такой язык и был назван ассемблером. Он стоит всего лишь на одну ступеньку выше машинных кодов, однако общаться с компьютером на таком языке несравненно проще, чем на языке цифр. Приведенная выше комбинация единиц и нулей 00111100 на ассемблере будет выглядеть так:
INC A
где INC - сокращение от английского слова increase (увеличиваться). Сразу же скажем, что сокращенные имена команд микропроцессора называют мнемониками. Запомните это слово хорошенько, так как оно не раз встретится в нашей книге.
Вот краткий и не совсем полный список операций, доступных микропроцессору:
10 LET ADDR1=16384 20 LET ADDR2=15880 30 LET N=8 40 LET A=PEEK (ADDR2) 50 POKE (ADDR1),A 60 LET ADDR1=ADDR1+256 70 LET ADDR2=ADDR2+1 80 LET N=N-1 90 IF N<>0 THEN GO TO 40Выполнив эту программку, вы увидите в верхнем левом углу экрана букву A. Наверное, нет большой необходимости подробно расписывать, как работает приведенный пример, тем не менее, кратко поясним, что же здесь происходит.
В переменную ADDR1 помещаем адрес (напоминаем, что адресом называется порядковый номер байта в памяти; в ZX Spectrum адреса имеют номера от 0 до 65535) начала экранной области памяти, а переменная ADDR2 указывает на начало данных, находящихся в ПЗУ и описывающих внешний вид символа A. В данном примере адрес ADDR2 рассчитан заранее, хотя обычно все вычисления возлагаются на программу. Далее в цикле последовательно считываются 8 байтов, составляющих символ, и переносятся на экран. При этом переменная ADDR1 изменяется с шагом 256, что обеспечивает заполнение одного знакоместа (чуть позже мы подробно остановимся на строении экрана и методах вычисления его адресов, а пока примите это как данность). Обратите внимание на способ организации цикла в этом примере. С точки зрения Бейсика вся эта программка выглядит довольно неказисто, но зато она довольно точно отражает последовательность действий микропроцессора при выполнении аналогичной задачи.
Вообще-то все на самом деле выглядит несколько сложнее, а здесь мы продемонстрировали лишь принцип работы одного из самых популярных операторов Бейсика - оператора PRINT. Но пусть вас это не пугает, ведь процедура вывода символов на экран уже имеется в компьютере, и совершенно не обязательно воспроизводить ее еще раз в своей собственной программе. Достаточно знать, как ее можно вызвать - и значительная часть проблем отойдет в сторону.
Однако, не будем забегать вперед, а прежде разберемся до конца с темой этой главы.
Итак, что же мы теряем и что приобретаем с переходом к более низким уровням программирования?
Преимущества:
Метод, используемый интерпретаторами можно сравнить с переводом со словарем. Микропроцессор последовательно считывает текст программы слово за словом, оператор за оператором, затем лезет в специальную таблицу, содержащую имена команд и адреса подпрограмм, выполняющих заданное действие. И только после того, как весь оператор прочитан до конца, начинается его исполнение. Не увеличивает скорость перевода еще и то, что у компьютера весьма «короткая память», и надо за каждым словом вновь и вновь лезть в словарь, даже если это слово только что встречалось.
Несколько быстрее работают компиляторы. Полученные с их помощью программы можно сравнить с подстрочником, составленным довольно неумелым переводчиком, поэтому микропроцессору над каждой фразой приходится еще поломать голову, что же хотел сказать этим автор. (Если быть более точным, компилятор каждую фразу исходного языка заменяет кусочком машинного кода, а то, как эффективно он это делает, зависит от авторов данного компилятора - Примеч. ред.) Кроме того, большинство компиляторов имеет дурную привычку «навешивать» на программу воз и маленькую тележку совершенно никому не нужного хлама, что при 48K максимальной свободной памяти кажется, мягко говоря, несколько расточительным.
Что же касается машинных кодов, то это родной язык компьютера, и совершенно естественно, что программу на таком языке микропроцессор может выполнить в самые кратчайшие сроки - ведь в этом случае не приходится прибегать к услугам переводчиков. Безусловно, и тут при желании можно «загнуть» такую заумную фразу, которая надолго оставит компьютер в недоумении, но это уже будет на совести автора программы.
Конечно, умение писать на ассемблере не означает полный отказ от Бейсика и других языков высокого уровня, особенно на первых порах. Поэтому мы ставим цель прежде всего научить вас создавать коротенькие фрагменты, позволяющие значительно обогатить игры и придать им динамичность. Большинство предлагаемых в этой книге подпрограмм построено по принципу широкоизвестного набора процедур в машинных кодах под названием Supercode. Причем некоторые из предлагаемых примеров будут работать в «тандеме» с программами на Бейсике.
| 65535 | ||
| ОЗУ | Определяемые пользователем символы | |
| UDG (23675) | ||
| Вершина машинного стека | ||
| RAMTOP (23730) | ||
| Машинный стек | ||
| Свободная память | ||
| STKEND (23653) | ||
| Рабочие области Бейсика | ||
| STKBOT (23651) | ||
| Стек калькулятора | ||
| WORKSP (23649) | ||
| Область редактирования строк бейсик-программ | ||
| ELINE (23641) | ||
| Переменные Бейсика | ||
| VARS (23627) | ||
| Текст бейсик-программы | ||
| PROG (23635) | ||
| Канальная информация | ||
| CHANS (23631) | ||
| Системные переменные | ||
| 23552 | ||
| Буфер принтера | ||
| 23296 | ||
| Видеобуфер | ||
| 16384 | ||
| ПЗУ | Знакогенератор | |
| 15616 | ||
| Операционная система Бейсик | ||
| 0 |
Рис. 2.1. Распределение областей памяти
Если в ПЗУ все уже предопределено, то оперативная память служит для временного хранения и обработки информации. Это могут быть различные программы на Бейсике или в машинных кодах, текстовые файлы, блоки данных и т. п. Все программы, которые приведены в книге, должны размещаться именно в оперативной памяти.
Для успешного программирования в машинных кодах и на ассемблере нужно четко представлять, какие области оперативной памяти для каких целей служат. Наиболее важной из них является видеобуфер, так как никакими программными средствами невозможно изменить его местоположение, размер или строение. Экранная память начинается с адреса 16384 и занимает 6912 байт. Вся остальная память, с адреса 23296 и до 65535 включительно, находится в вашем безраздельном распоряжении. Правда, это только в том случае, если вы создаете программу, полностью независимую от операционной системы компьютера. Но пока программа не заблокирует систему, вы не можете нарушать содержимого и структуры некоторых областей, о назначении и расположении которых вы должны быть хорошо осведомлены, начиная программировать на ассемблере.
Однако нужно помнить, что все сказанное о буфере принтера справедливо лишь для стандартной конфигурации компьютера, то есть для ZX Spectrum 48. Если вы пишете программы, которые должны работать на модели Spectrum 128 или Scorpion ZS 256, то столь произвольно обращаться с этой областью памяти нельзя, потому как в данных адресах указанные модели содержат жизненно важную информацию, при разрушении которой компьютер не сможет нормально продолжать работу (хотя, разумеется, можно выполнить программу и в режиме «эмуляции» обычного Speccy - Примеч. ред.).
С адреса 23552 начинается наиболее важная из системных областей. Вы уже частично (а может быть, и полностью) знакомы с системными переменными Бейсика. В различных ячейках этой области хранится различная информация о текущем состоянии всех без исключения параметров операционной системы, в том числе и информация о расположении всех прочих областей памяти, которые не имеют жесткой привязки к конкретным адресам (описание всех системных переменных Spectrum-Бейсика, а также ZX Spectrum 128 и TR-DOS можно найти в [2]).
Системная переменная CHANS, находящаяся в ячейках 23631 и 23632, адресует область канальной информации, содержащей необходимые сведения о расположении процедур ввода/вывода (напоминаем, что на первом месте стоит младший байт адреса и для перевода двухбайтового значения в число требуется содержимое старшего байта умножить на 256 и прибавить к нему число из младшего байта; например, для определения значения переменной CHANS нужно выполнить команду PRINT PEEK 23631+256*PEEK 23632). Далее следует область, хранящая текст бейсик-программы. Ее начальный адрес содержит переменная PROG (23635/23636). Сразу за бейсик-программой располагаются переменные Бейсика. Их начало можно определить, прочитав значение системной переменной VARS по адресу 23627/23628. После переменных Бейсика расположена область, предназначенная для ввода и редактирования строк бейсик-программ. Ее адрес записан в системной переменной E_LINE (23461/23642). За областью редактирования строк находится рабочая область Бейсика WORKSP (23649/23650), предназначенная для самых разных нужд. Сюда, например, считываются заголовки файлов при загрузке программ с ленты, там же размещаются строки загружаемой оператором MERGE программы до объединения их со строками программы в памяти и т. д.
Следом за областью WORKSP расположена весьма важная область, называемая стеком калькулятора. Название говорит само за себя: сюда записываются числовые значения, над которыми производятся различные математические операции, здесь же остается до востребования и результат расчетов. В дальнейшем мы не раз будем прибегать к помощи этой области, так как многие процедуры операционной системы, которыми мы будем пользоваться, берут параметры именно отсюда. Системная переменная STKBOT (23651/23652) указывает на начало стека калькулятора, а STKEND (23653/23654) - на его вершину. Иногда бывает важно учитывать, что каждое значение, заносимое на вершину стека калькулятора, имеет длину 5 байт.
Системная переменная RAMTOP (23730/23731) указывает на местоположение в памяти еще одной важной области - машинного стека (не путайте со стеком калькулятора!). Но надо помнить, что в ассемблерных программах стек вполне может потерять всякую связь с RAMTOP, ибо он не является неотъемлемой частью бейсик-системы, а скорее уж, находится в «собственности» микропроцессора. Вообще же стек - это удивительно удобная штука для временного хранения различной информации, потому как при его использовании не приходится запоминать, где, по какому адресу или в какой переменной находится то или иное число. Важно лишь соблюсти очередность обмена данными, а чтобы не нарушить установленный порядок, следует знать, по какому принципу работает стек. Этот принцип часто называют «Last In, First Out» (LIFO), что значит «Последним вошел, первым вышел». Совсем как в автобусе в час пик - чтобы выпустить какого-нибудь пассажира, прежде должны выйти все вошедшие за ним. Поэтому данные, которые понадобятся в первую очередь нужно заносить в стек последними (это же, кстати, в полной мере относится и к порядку обмена данными со стеком калькулятора).
Говоря о машинном стеке, нужно отметить один довольно интересный факт. В отличие от способа организации других областей памяти (а также и от стека калькулятора) он растет «головой вниз», то есть каждое следующее значение, отправленное в стек, будет располагаться по адресу на 2 байта ниже предыдущего (машинный стек работает только с двухбайтовыми величинами). Поэтому вас не должны вводить в заблуждение такие выражения как «Положить значение на вершину стека» или «Снять значение с вершины стека» - эта самая «вершина» всегда будет не выше основания.
Существуют и другие области памяти, как то: UDG, системные переменные TR-DOS или карта микродрайва. Область определяемых пользователем символов UDG мы рассмотрим в следующих главах, а о других разделах памяти (в том числе и об архитектуре Spectrum 128) вы можете получить дополнительные сведения, например, в книге [2].
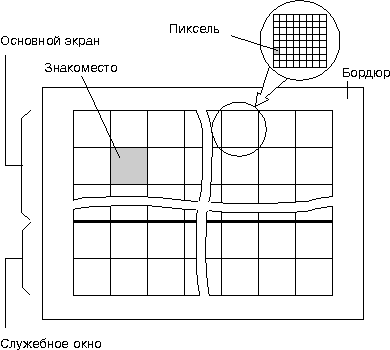
Строение экрана «на высоком уровне» вам уже должно быть известно (рис. 2.2), но тем не менее, напомним, из каких частей он состоит. Внешняя область, называемая бордюром, может только изменять свой цвет, никакую графическую информацию, за исключением быстро бегущих по нему полос, в эту область поместить невозможно. Внутри бордюра находится рабочий экран, сюда может быть выведена любая текстовая или графическая информация. Говоря об экране, мы всегда будем подразумевать именно эту его часть. Рабочий экран в свою очередь делится на основной экран и служебное окно, которое обычно занимает две нижние строки, но в некоторых случаях может увеличиваться или уменьшаться. Всего экран имеет 24 текстовые строки, и в каждой строке можно напечатать 32 символа. Эти стандартные площадки для вывода символов называются знакоместами. Любое изображение на экране состоит из маленьких квадратиков, называемых пикселями, и каждое знакоместо имеет размеры 8 ґ 8 таких элементарных «точек».
Рис. 2.2. Строение экрана
Теперь перейдем к более низкому уровню и посмотрим, как адресуется область видеобуфера. Вы, наверное, не раз наблюдали, как грузятся с магнитофона стандартные экранные файлы: область экрана заполняется не последовательно, строка за строкой, а довольно хитрым способом. Сначала один за другим появляются верхние ряды пикселей восьми первых текстовых строк, затем в этих же строках рисуются все вторые ряды и так далее, пока не сформируется изображение всей верхней трети экрана. Затем, в том же порядке, заполняется средняя часть экрана, а потом и нижняя. И только в самом конце последовательно выводятся атрибуты всех знакомест. Однако это говорит не о каком-то изощренном способе загрузки именно экранных файлов - они грузятся так же, как и любые другие, последовательно заполняя ячейки памяти от младших адресов к старшим. Это свидетельствует, напротив, о нелинейном строении экранной области памяти.
На первый взгляд такая организация экранной области кажется исключительно неудобной, особенно при решении задач определения адреса по заданным координатам. Но это лишь до тех пор, пока вы используете в расчетах только десятичные числа. Ведь даже начальный адрес видеобуфера 16384 в десятичном виде представляется просто «взятым с потолка». В таких случаях гораздо удобнее пользоваться несколько иным представлением числовой информации. Мы имеем в виду шестнадцатеричный формат чисел, который от десятичного отличается «емкостью» разрядов.
В десятичном представлении каждый разряд числа может изменяться от 0 до 9, а в шестнадцатеричном - от 0 до 15. Цифры от 0 до 9 при этом записываются так же, как и в десятичных числах, а дальше применяются буквы латинского алфавита от A до F. Вот соответствие чисел в десятичном и шестнадцатеричном форматах:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18... 0 1 2 3 4 5 6 7 8 9 A B C D E F 10 11 12...Если адрес 16384 привести к шестнадцатеричному виду, то он вдруг окажется совершенно «ровным» - #4000 (знак # перед числом говорит о том, что оно представлено как шестнадцатеричное). Взгляните на схему, изображенную на рис. 2.3 и вы заметите явную закономерность в распределении адресного пространства видеообласти. В недалеком будущем мы подробно расскажем о методах вычисления адресов экрана, а сейчас перейдем к рассмотрению других не менее важных понятий.
| Данные | Атриб. | Строка | ВИДЕОБУФЕР | Строка | Данные | Атриб. |
| #4000 | #5800 | 0 | 0 | #401F | #581F | |
| #4020 | #5820 | 1 | 1 | #403F | #583F | |
| #4040 | #5840 | 2 | 2 | #405F | #585F | |
| #4060 | #5860 | 3 | 3 | #407F | #587F | |
| #4080 | #5880 | 4 | 4 | #409F | #589F | |
| #40A0 | #58A0 | 5 | 5 | #40BF | #58BF | |
| #40C0 | #58C0 | 6 | 6 | #40DF | #58DF | |
| #40E0 | #58E0 | 7 | 7 | #40FF | #58FF | |
| #4800 | #5900 | 8 | 8 | #481F | #591F | |
| #4820 | #5920 | 9 | 9 | #483F | #593F | |
| #4840 | #5940 | 10 | 10 | #485F | #595F | |
| #4860 | #5960 | 11 | 11 | #487F | #597F | |
| #4880 | #5980 | 12 | 12 | #489F | #599F | |
| #48A0 | #59A0 | 13 | 13 | #48BF | #59BF | |
| #48C0 | #59C0 | 14 | 14 | #48DF | #59DF | |
| #48E0 | #59E0 | 15 | 15 | #48FF | #59FF | |
| #5000 | #5A00 | 16 | 16 | #501F | #5A1F | |
| #5020 | #5A20 | 17 | 17 | #503F | #5A3F | |
| #5040 | #5A40 | 18 | 18 | #505F | #5A5F | |
| #5060 | #5A60 | 19 | 19 | #507F | #5A7F | |
| #5080 | #5A80 | 20 | 20 | #509F | #5A9F | |
| #50A0 | #5AA0 | 21 | 21 | #50BF | #5ABF | |
| #50C0 | #5AC0 | 22 | 22 | #50DF | #5ADF | |
| #50E0 | #5AE0 | 23 | 23 | #50FF | #5AFF |
Мы назвали регистры особыми ячейками, но в чем же их особенность и чем они отличаются от ячеек обычной оперативной памяти? В первую очередь их особенность проявляется в том, что регистры не равноценны, то есть действия, допустимые с использованием одного регистра невозможны с другими и наоборот. Кроме того, если значения одних регистров можно изменять непосредственно, записывая в них те или иные числа, то другие изменяются автоматически, и узнать их содержимое возможно только лишь косвенными методами.
Другая особенность регистров состоит в том, что для обращения к ним используются не адреса, а собственные имена, состоящие из одной или двух букв латинского алфавита (конечно же, имена присутствуют только в языке ассемблера, а не в машинных кодах команд).
Есть и еще одно свойство, отличающее регистры от ячеек памяти - это способность их объединяться определенным образом, составляя регистровые пары. Во всем же остальном они очень схожи с отдельными ячейками памяти компьютера. Они также имеют размер байта (8 бит), в них можно записывать числа и читать их значение (за исключением системных регистров), информация в них может сохраняться, как и в памяти, до тех пор, пока не будет изменена программой.
Все регистры могут быть подразделены на несколько групп, учитывая характер функций, которые они выполняют. Начнем с самой многочисленной и наиболее важной группы - с так называемых регистров общего назначения или регистров данных. Их насчитывается семь: A, B, C, D, E, H и L. Как уже говорилось, каждый регистр может использоваться лишь в строго определенных операциях и каждый из них в этом смысле уникален. Например, регистр A (часто называемый аккумулятором) участвует во всех арифметических и логических операциях, результат которых мы получаем в том же регистре A. Использование регистра B наиболее удобно при организации циклов. При этом он выполняет роль, схожую с обязанностями управляющих переменных циклов FOR...NEXT в Бейсике. Другие регистры проявляют свою индивидуальность, преимущественно, объединившись в пары. Возможны следующие регистровые пары: BC, DE и HL. И вам следует запомнить, что никаких других вариантов соединения регистров не существует.
Из сказанного может создаться впечатление, что аккумулятор остался в одиночестве, не найдя своей половинки. Однако это не совсем так. На самом деле существует пара и для него. Просто пока мы сознательно умалчиваем об этом, так как регистр, дополняющий аккумулятор до пары, имеет совершенно особый статус и заслуживает отдельного разговора, который мы поведем в разделе «Организация циклов в ассемблере» главы 5.
Каждая из регистровых пар так же, как и любой из отдельных регистров, выполняет вполне конкретные, возложенные именно на нее функции. Так пара BC часто используется, подобно регистру B в качестве счетчика в циклах. HL несет наибольшую нагрузку, играя примерно ту же роль, что и аккумулятор: только с этой парой можно выполнять арифметические действия. Пара DE зачастую адресует пункт назначения при перемещениях данных из одной области памяти в другую.
Работая с регистровыми парами, приходится иметь дело с двухбайтовыми величинами. Поэтому необходимо четко представлять, как такие числа хранятся в памяти и каким образом они размещаются на регистрах. В Бейсике вам, вероятно, уже доводилось сталкиваться с подобной задачей. Если вы пользовались оператором POKE и функцией PEEK, например, для изменения или чтения системных переменных, то вам уже должно быть известно, что двухбайтовые значения хранятся в памяти, как правило, в обратном порядке - сначала младший байт, затем старший. Это можно продемонстрировать на таких примерах: число 1 запишется в памяти в виде последовательности байтов 1 и 0; у числа 255 старшая часть также равна нулю, поэтому оно будет представлено как 255 и 0; следующее число 256, расположившись в двух ячейках, будет выглядеть как 0 и 1. На всякий случай напомним вам способ, позволяющий разложить любое число из диапазона 0...65535 на два байта и определить значения старшей и младшей половинки:
LET high= INT(N/256): REM Старшая часть LET low=N-256*high: REM Младшая частьВам также часто придется сталкиваться с необходимостью изменять только старший или только младший регистр в регистровых парах. Поэтому следует хорошенько запомнить правило, которому подчиняются регистры при объединении. Оказывается, порядок здесь прямо противоположный по сравнению с числами в памяти - первым записывается старший регистр, а за ним младший. То есть в паре BC старшим окажется регистр B, в DE - D, а в HL - H. Чтобы лучше запомнить это, можете представить имя регистровой пары HL как сокращения английских слов HIGH (высокий, старший) и LOW (низкий, младший), а то, что порядок следования старшей и младшей половинок в остальных парах аналогичен, это уже само собой разумеется.
К следующей группе относятся два индексных регистра, имена которых начинаются с буквы I (Index) - IX и IY. В отличие от регистров данных, индексные регистры состоят из 16 разрядов, то есть являются как бы неделимыми регистровыми парами. (На самом деле существуют методы разделения индексных регистров на 8-разрядные половинки, что уже относится к программистским изощрениям. Об этих методах вы можете узнать из Приложения II.) В основном они применяются при обработке блоков данных, массивов или разного рода таблиц, но также вполне могут использоваться и как обычные регистры общего назначения. Удобство употребления этих регистров заключается в том, что они позволяют обратиться к любому элементу массива или таблицы без изменения содержимого самого регистра, а лишь указанием величины смещения для данного элемента (иначе, его номера или индекса, например, IX+5). Заметим, что регистр IY обычно адресует область системных переменных Бейсика и поэтому отчасти и только в компьютерах ZX Spectrum может быть отнесен к следующей группе - системным регистрам.
К системным или иначе - аппаратным регистрам относятся: указатель вершины стека SP (Stack Point), вектор прерываний I (Interrupt) (точнее, этот регистр содержит старший байт адреса векторов прерываний; позднее мы подробно расшифруем это понятие) и регистр регенерации R. Первый из них, так же, как и индексные регистры, имеет 16 разрядов, разделить которые на 8-битовые половинки нет никакой возможности. Но это и не нужно, ведь регистр SP служит для вполне определенных целей - указывает адрес вершины области машинного стека, как это и следует из его названия. Хотя с ним и можно обращаться, как с обычным регистром данных (записывать или читать из него информацию), но делать это нужно, совершенно точно представляя, что при этом происходит. Обычно же за регистром SP следит микропроцессор и изменяет его так, как надо при выполнении некоторых команд. Например, без этого регистра оказались бы совершенно невозможны вызовы подпрограмм с нормальным возвратом из них в основную программу.
Регистры I и R, в противоположность всем прочим, никогда не объединяются в пары и существуют только по отдельности. Содержимое вектора прерываний I также может быть изменено программным путем, однако делать этого не стоит до тех пор, пока вы не разберетесь с таким достаточно сложным вопросом, как прерывания. Что же касается регистра R, то читать из него можно, а вот записывать в него информацию в большинстве случаев бесполезно, так как он изменяется аппаратно. Правда, используется для аппаратных нужд только 7 младших разрядов, так что, если вам для чего-то окажется достаточно одного бита, можете хранить его в старшем разряде регистра регенерации.
В свое время мы подробно расскажем о применении всех существующих регистров, а сейчас закончим этот краткий обзор и займемся другими вопросами.
Большинство программ на машинном языке, имеющих возврат в Бейсик, заканчивается кодом 201 (в мнемоническом обозначении - RET), который аналогичен оператору RETURN. Поэтому простейшая программа может состоять всего из одного байта. Давайте сейчас создадим такую программу, а потом и выполним ее. Введите с клавиатуры оператор
POKE 40000,201а затем, чтобы проверить действие полученной «программы», запустите ее с помощью функции USR, например, так:
RANDOMIZE USR 40000Вроде бы ничего особенного не произошло - никаких видимых или слышимых эффектов. Но, по крайней мере, ваш компьютер выдержал подобное испытание и при этом не «завис» и не «сбросился» (если он исправен, конечно, на что мы надеемся). Программа нормально завершила свою работу и благополучно вышла в Бейсик с сообщением 0 OK.
Теперь попробуем запустить ее несколько иным способом. Заменим оператор RANDOMIZE на PRINT:
PRINT USR 40000То, что вы увидели на экране - весьма существенно и может очень пригодиться в будущем. Компьютер напечатал то же самое число, которое мы использовали в качестве аргумента функции USR. Можете проверить, что это не случайное совпадение, введя строку
POKE 40001,201: PRINT USR 40001Можете попробовать проделать то же самое и с другими адресами, только не слишком увлекайтесь, чтобы не залезть в «запрещенные» области памяти. Для подобных экспериментов лучше не выходить из диапазона адресов от 30000 до 60000, да и то лишь в том случае, если память компьютера свободна от каких-либо других программ.
Для того, чтобы каким-то образом использовать полученный результат, необходимо понять причину такого странного поведения компьютера. Ответ на эту загадку заключается в том, что USR - это функция, а любая функция, по своему определению, должна получать что-то на входе и возвращать нечто на выходе. Поэтому остается лишь выяснить сущность этих «что-то» и «нечто» - и вопрос можно считать решенным.
Как вы увидите позже, большинство процедур в машинных кодах, если это необходимо, получают входные параметры и возвращают значения на регистрах. Как правило, это оказывается наиболее удобно. Поскольку функция USR предназначена для вызова машинных процедур, то и она может обмениваться числовыми данными с программой на Бейсике также через регистры, а именно - через регистровую пару BC. В качестве входного параметра используется аргумент функции, а на выходе значение пары BC передается бейсик-программе. А так как в приведенных выше примерах никакие регистры не изменялись, то и на экране появлялось то же самое число, которое использовалось в качестве аргумента.
Теперь модернизируем нашу программку так, чтобы содержимое регистровой пары BC изменялось. Можно, например, просто записать в нее какое-нибудь число. Обычно запись в регистры числовых значений называют загрузкой, поэтому в мнемоническом обозначении такие команды начинаются с LD (сокращение от известного вам по Бейсику слова LOAD - загрузить). А выражение «загрузить регистровую пару BC значением 1000» записывается как
LD BC,1000
Эта команда всегда состоит из трех байт: первый равен 1, а второй и третий соответствуют двухбайтовому представлению числа в памяти. Таким образом, программа из двух команд
LD BC,1000
RET
в памяти будет представлена последовательностью кодов
1, 232, 3 и 201Введите их последовательно, начиная, например, с адреса 60000 и выполните закодированную программку оператором
PRINT USR 60000Если вы ничего не напутали, то на экране должно появиться число 1000.
Надо думать, на этих примерах вы уже почувствовали «прелесть» программирования в машинных кодах и догадались, что подобным методом может пользоваться только сумасшедший или неукротимый фанатик. Однако и фанатик в конце концов понимает, что лучше все же воспользоваться ассемблером, благо фирма HISOFT подарила синклеристам весьма недурную реализацию этого языка, по многим параметрам могущую считаться вполне профессиональной. (Лучшей реализацией языка ассемблера для компьютеров семейства ZX Spectrum считается транслятор фирмы OCEAN Software из пакета Laser Genius, однако ассемблер фирмы HISOFT остается непревзойденным по минимальному объему занимаемой самим транслятором памяти и, соответственно, максимальному размеру области, отводимой для создаваемого им кода программы. Как и Бейсик 48, этот ассемблер использует несколько усеченный строчный текстовый редактор. Это, конечно, немного хуже, чем экранный редактор (как, например, в Бейсике 128), но за все приходится чем-то расплачиваться - Примеч. ред.)
 Глава 1 Глава 1 |
Глава 3
